Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this issue exists on the latest version of pandas.
-
[x] I have confirmed this issue exists on the main branch of pandas.
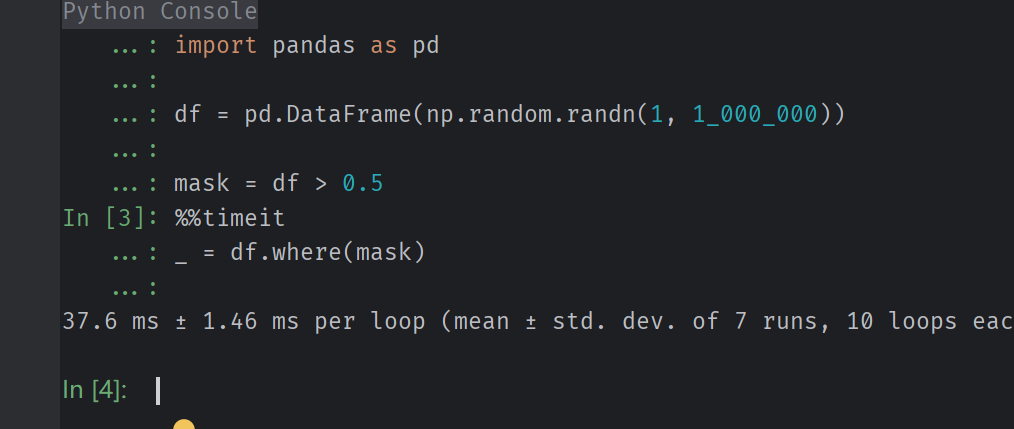
Reproducible Example
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(1, 1_000_000))
mask = df > 0.5
%%timeit
_ = df.where(mask)
# 693 ms ± 3.49 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
perf result taken from pyinstrument:
This issue seems to be related to this: https://github.com/pandas-dev/pandas/blob/d1ec1a4c9b58a9ebff482af2b918094e39d87893/pandas/core/generic.py#L9735-L9737
When dataframe is large, this overhead of is_bool_dtype accumulates. Would it be better to use cond.dtypes.unique() instead?
Installed Versions
Prior Performance
No response
Comment From: samukweku
Hi @auderson do U have a benchmark U r comparing against?
Comment From: auderson
@samukweku No, but I do find the % of time spent by is_bool_dtype increases with the num of columns.
Comment From: samukweku
a crude benchmark, comparing against numpy:
np.random.seed(3)
df = pd.DataFrame(np.random.randn(1, 1_000_000))
mask = df > 0.5
%timeit pd.DataFrame(np.where(mask, df, np.nan), columns= df.columns)
573 μs ± 102 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit df.where(mask)
324 ms ± 1.28 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
pd.DataFrame(np.where(mask, df, np.nan), columns= df.columns).equals(df.where(mask))
Out[14]: True
Comment From: samukweku
@auderson i think there is an expense associated with .unique though, so i'm not sure it would offer better performance. maybe you could test it locally?
Comment From: auderson
@samukweku
From my local machine the performance increases by 10x if using .dtypes.unique()
But a better solution is to get the dtypes of each block, instead of dtypes of each column, then .dtypes.unique() will not be needed. e.g. [blk.dtype for blk in df._mgr.blocks]
I'm not familiar with pandas internals so not sure if the above usage is OK