This is an issue to collect feedback on the decision to make PyArrow a required dependency and to infer strings as PyArrow backed strings by default.
The background for this decision can be found here: https://pandas.pydata.org/pdeps/0010-required-pyarrow-dependency.html
If you would like to filter this warning without installing pyarrow at this time, please view this comment: https://github.com/pandas-dev/pandas/issues/54466#issuecomment-1919988166
Comment From: mynewestgitaccount
Something that hasn't received enough attention/discussion, at least in my mind, is this piece of the Drawbacks section of the PDEP (bolding added by me):
Including PyArrow would naturally increase the installation size of pandas. For example, installing pandas and PyArrow using pip from wheels, numpy and pandas requires about 70MB, and including PyArrow requires an additional 120MB. An increase of installation size would have negative implication using pandas in space-constrained development or deployment environments such as AWS Lambda.
I honestly don't understand how mandating a 170% increase in the effective size of a pandas installation (70MB to 190MB, from the numbers in the quoted text) can be considered okay.
For that kind of increase, I would expect/want the tradeoff to be major improvements across the board. Instead, this change comes with limited benefit but massive bloat for anyone who doesn't need the features PyArrow enables, e.g. for those who don't have issues with the current functionality of pandas.
Comment From: rebecca-palmer
Debian/Ubuntu have system packages for pandas but not pyarrow, which would no longer be possible. (System packages are not allowed to depend on non-system packages.)
I don't know whether creating a system package of pyarrow is possible with reasonable effort, or whether this would make the system pandas packages impossible to update (and eventually require their removal when old pandas was no longer compatible with current Python/numpy).
Comment From: mroeschke
For that kind of increase, I would expect/want the tradeoff to be major improvements across the board.
Yeah unfortunately this is where the subjective tradeoff comes into effect. pytz and dateutil as required dependencies have a similar issue for users who do not need timezone or date parsing support respectively. The hope with pyarrow is that the tradeoff improves the current functionality for common "object" types in pandas such as text, binary, decimal, and nested data.
Debian/Ubuntu have system packages for pandas but not pyarrow, which would no longer be possible.
AFAIK most pydata projects don't actually publish/manage Linux system packages for their respective libraries. Do you know how these are packaged today?
Comment From: mynewestgitaccount
pytz and dateutil as required dependencies have a similar issue for users who do not need timezone or date parsing support respectively.
The pytz and dateutil wheels are only ~500kb. Drawing a comparison between them and PyArrow seems like a stretch, to put it lightly.
Comment From: rebecca-palmer
Do you know how these are packaged today?
By whoever offers to do it, currently me for pandas. Of the pydata projects, Debian currently has pydata-sphinx-theme, sparse, patsy, xarray and numexpr.
An old discussion thread (anyone can post there, but be warned that doing so will expose your non-spam-protected email address) suggests that there is existing work on a pyarrow Debian package, but I don't yet know whether it ever got far enough to work.
Comment From: rebecca-palmer
I do intend to investigate this further at some point - I haven't done so yet because Debian updated numexpr to 2.8.5, breaking pandas (#54449 / #54546), and fixing that is currently more urgent.
Comment From: jjerphan
Hi,
Thanks for welcoming feedback from the community.
While I respect you decision, I am afraid that making pyarrow a required dependency will come with costly consequences for users and downstream libraries' developers and maintainers for two reasons:
- installing pyarrow after pandas in a fresh conda environment increases its size from approximately 100MiB to approximately 500 MiB.
Packages size
libgoogle-cloud-2.12.0-h840a212_1 : 46106632 bytes,
python-3.11.4-hab00c5b_0_cpython : 30679695 bytes,
libarrow-12.0.1-h10ac928_8_cpu : 27696900 bytes,
ucx-1.14.1-h4a2ce2d_3 : 15692979 bytes,
pandas-2.0.3-py311h320fe9a_1 : 14711359 bytes,
numpy-1.25.2-py311h64a7726_0 : 8139293 bytes,
libgrpc-1.56.2-h3905398_1 : 6331805 bytes,
libopenblas-0.3.23-pthreads_h80387f5_0 : 5406072 bytes,
aws-sdk-cpp-1.10.57-h85b1a90_19 : 4055495 bytes,
pyarrow-12.0.1-py311h39c9aba_8_cpu : 3989550 bytes,
libstdcxx-ng-13.1.0-hfd8a6a1_0 : 3847887 bytes,
rdma-core-28.9-h59595ed_1 : 3735644 bytes,
libthrift-0.18.1-h8fd135c_2 : 3584078 bytes,
tk-8.6.12-h27826a3_0 : 3456292 bytes,
openssl-3.1.2-hd590300_0 : 2646546 bytes,
libprotobuf-4.23.3-hd1fb520_0 : 2506133 bytes,
libgfortran5-13.1.0-h15d22d2_0 : 1437388 bytes,
pip-23.2.1-pyhd8ed1ab_0 : 1386212 bytes,
krb5-1.21.2-h659d440_0 : 1371181 bytes,
libabseil-20230125.3-cxx17_h59595ed_0 : 1240376 bytes,
orc-1.9.0-h385abfd_1 : 1020883 bytes,
ncurses-6.4-hcb278e6_0 : 880967 bytes,
pygments-2.16.1-pyhd8ed1ab_0 : 853439 bytes,
jedi-0.19.0-pyhd8ed1ab_0 : 844518 bytes,
libsqlite-3.42.0-h2797004_0 : 828910 bytes,
libgcc-ng-13.1.0-he5830b7_0 : 776294 bytes,
ld_impl_linux-64-2.40-h41732ed_0 : 704696 bytes,
libnghttp2-1.52.0-h61bc06f_0 : 622366 bytes,
ipython-8.14.0-pyh41d4057_0 : 583448 bytes,
bzip2-1.0.8-h7f98852_4 : 495686 bytes,
setuptools-68.1.2-pyhd8ed1ab_0 : 462324 bytes,
zstd-1.5.2-hfc55251_7 : 431126 bytes,
libevent-2.1.12-hf998b51_1 : 427426 bytes,
libgomp-13.1.0-he5830b7_0 : 419184 bytes,
xz-5.2.6-h166bdaf_0 : 418368 bytes,
libcurl-8.2.1-hca28451_0 : 372511 bytes,
s2n-1.3.48-h06160fa_0 : 369441 bytes,
aws-crt-cpp-0.21.0-hb942446_5 : 320415 bytes,
readline-8.2-h8228510_1 : 281456 bytes,
libssh2-1.11.0-h0841786_0 : 271133 bytes,
prompt-toolkit-3.0.39-pyha770c72_0 : 269068 bytes,
libbrotlienc-1.0.9-h166bdaf_9 : 265202 bytes,
python-dateutil-2.8.2-pyhd8ed1ab_0 : 245987 bytes,
re2-2023.03.02-h8c504da_0 : 201211 bytes,
aws-c-common-0.9.0-hd590300_0 : 197608 bytes,
aws-c-http-0.7.11-h00aa349_4 : 194366 bytes,
pytz-2023.3-pyhd8ed1ab_0 : 186506 bytes,
aws-c-mqtt-0.9.3-hb447be9_1 : 162493 bytes,
aws-c-io-0.13.32-h4a1a131_0 : 154523 bytes,
ca-certificates-2023.7.22-hbcca054_0 : 149515 bytes,
lz4-c-1.9.4-hcb278e6_0 : 143402 bytes,
python-tzdata-2023.3-pyhd8ed1ab_0 : 143131 bytes,
libedit-3.1.20191231-he28a2e2_2 : 123878 bytes,
keyutils-1.6.1-h166bdaf_0 : 117831 bytes,
tzdata-2023c-h71feb2d_0 : 117580 bytes,
gflags-2.2.2-he1b5a44_1004 : 116549 bytes,
glog-0.6.0-h6f12383_0 : 114321 bytes,
c-ares-1.19.1-hd590300_0 : 113362 bytes,
libev-4.33-h516909a_1 : 106190 bytes,
aws-c-auth-0.7.3-h28f7589_1 : 101677 bytes,
libutf8proc-2.8.0-h166bdaf_0 : 101070 bytes,
traitlets-5.9.0-pyhd8ed1ab_0 : 98443 bytes,
aws-c-s3-0.3.14-hf3aad02_1 : 86553 bytes,
libexpat-2.5.0-hcb278e6_1 : 77980 bytes,
libbrotlicommon-1.0.9-h166bdaf_9 : 71065 bytes,
parso-0.8.3-pyhd8ed1ab_0 : 71048 bytes,
libzlib-1.2.13-hd590300_5 : 61588 bytes,
libffi-3.4.2-h7f98852_5 : 58292 bytes,
wheel-0.41.1-pyhd8ed1ab_0 : 57374 bytes,
aws-c-event-stream-0.3.1-h2e3709c_4 : 54050 bytes,
aws-c-sdkutils-0.1.12-h4d4d85c_1 : 53123 bytes,
aws-c-cal-0.6.1-hc309b26_1 : 50923 bytes,
aws-checksums-0.1.17-h4d4d85c_1 : 50001 bytes,
pexpect-4.8.0-pyh1a96a4e_2 : 48780 bytes,
libnuma-2.0.16-h0b41bf4_1 : 41107 bytes,
snappy-1.1.10-h9fff704_0 : 38865 bytes,
typing_extensions-4.7.1-pyha770c72_0 : 36321 bytes,
libuuid-2.38.1-h0b41bf4_0 : 33601 bytes,
libbrotlidec-1.0.9-h166bdaf_9 : 32567 bytes,
libnsl-2.0.0-h7f98852_0 : 31236 bytes,
wcwidth-0.2.6-pyhd8ed1ab_0 : 29133 bytes,
asttokens-2.2.1-pyhd8ed1ab_0 : 27831 bytes,
stack_data-0.6.2-pyhd8ed1ab_0 : 26205 bytes,
executing-1.2.0-pyhd8ed1ab_0 : 25013 bytes,
_openmp_mutex-4.5-2_gnu : 23621 bytes,
libgfortran-ng-13.1.0-h69a702a_0 : 23182 bytes,
libcrc32c-1.1.2-h9c3ff4c_0 : 20440 bytes,
aws-c-compression-0.2.17-h4d4d85c_2 : 19105 bytes,
ptyprocess-0.7.0-pyhd3deb0d_0 : 16546 bytes,
pure_eval-0.2.2-pyhd8ed1ab_0 : 14551 bytes,
libblas-3.9.0-17_linux64_openblas : 14473 bytes,
liblapack-3.9.0-17_linux64_openblas : 14408 bytes,
libcblas-3.9.0-17_linux64_openblas : 14401 bytes,
six-1.16.0-pyh6c4a22f_0 : 14259 bytes,
backcall-0.2.0-pyh9f0ad1d_0 : 13705 bytes,
matplotlib-inline-0.1.6-pyhd8ed1ab_0 : 12273 bytes,
decorator-5.1.1-pyhd8ed1ab_0 : 12072 bytes,
backports.functools_lru_cache-1.6.5-pyhd8ed1ab_0 : 11519 bytes,
pickleshare-0.7.5-py_1003 : 9332 bytes,
prompt_toolkit-3.0.39-hd8ed1ab_0 : 6731 bytes,
backports-1.0-pyhd8ed1ab_3 : 5950 bytes,
python_abi-3.11-3_cp311 : 5682 bytes,
_libgcc_mutex-0.1-conda_forge : 2562 bytes,
pyarrowalso depends onlibarrowwhich itself depends on several notable C and C++ libraries. This constraints the installation of other packages whose dependencies might be incompatible withlibarrow's, making pandas potentially unusable in some context.
Have you considered those two observations as drawbacks before taking the decision?
Comment From: lithomas1
Hi,
Thanks for welcoming feedback from the community.
While I respect you decision, I am afraid that making
pyarrowa required dependency will come with costly consequences for users and downstream libraries' developers and maintainers for two reasons:
- installing pyarrow after pandas in a fresh conda environment increases its size from approximately 100MiB to approximately 500 MiB.
Packages size *
pyarrowalso depends onlibarrowwhich itself depends on several notable C and C++ libraries. This constraints the installation of other packages whose dependencies might be incompatible withlibarrow's, making pandas potentially unusable in some context.Have you considered those two observations as drawbacks before taking the decision?
This is discussed a bit in https://github.com/pandas-dev/pandas/pull/52711/files#diff-3fc3ce7b7d119c90be473d5d03d08d221571c67b4f3a9473c2363342328535b2R179-R193 (for pip only I guess).
While currently the build size for pyarrow is pretty large, it doesn't "have" to be that big. I think by pandas 3.0 (when pyarrow will actually become required), at least some components will be spun out/made optional/something like that (I heard that the arrow people were talking about this).
(cc @jorisvandenbossche for more info on this)
I'm not an Arrow dev myself, but if is something that just needs someone to look at, I'm happy to put some time in help give Arrow a nudge in the right direction.
Finally, for clarity purposes, is the reason for concern also AWS lambda/pyodide/Alpine, or something else?
(IMO, outside of stuff like lambda funcs, pyarrow isn't too egregious in terms of package size compared to pytorch/tensorflow but it's definetely something that can be improved)
Comment From: jjerphan
If libarrow is slimmed down by having non-essential Arrow features be extracted into other libraries which could be optional dependencies, I think most people's concerns would be addressed.
Edit: See https://github.com/conda-forge/arrow-cpp-feedstock/issues/1035
Comment From: DerThorsten
Hi,
Thanks for welcoming feedback from the community. For wasm builds of python / python-packages (ie pyodide / emscripten-forge) package size really matters since these packages have to be downloaded from within the browser. Once a package is too big, usability suffers drastically.
With pyarrow as a required dependency, pandas is less usable from python in the browser.
Comment From: surfaceowl
Debian/Ubuntu have system packages for pandas but not pyarrow, which would no longer be possible. (System packages are not allowed to depend on non-system packages.)
I don't know whether creating a system package of pyarrow is possible with reasonable effort, or whether this would make the system pandas packages impossible to update (and eventually require their removal when old pandas was no longer compatible with current Python/numpy).
There is another way - use virtual environments in user space instead of system python. The Python Software Foundation recommends users create virtual environments; and Debian/Ubuntu want users to leave the system python untouched to avoid breaking system python.
Perhaps Pandas could add some warnings or error messages on install to steer people to virtualenv. This approach might avoid or at least defer work of adding pyarrow to APT as well as the risks of users breaking system python. Also which I'm building projects I might want a much later version of pandas/pyarrow than would ever ship on Debian given the release strategy/timing delay.
On the other hand, arrow backend has significant advantages and with the rise of other important packages in the data space that also use pyarrow (polars, dask, modin), perhaps there is sufficient reason to add pyarrow to APT sources.
A good summary that might be worth checking out is Externally managed environments. The original PEP 668 is found here.
Comment From: stonebig
I think it's the rigth path for performance in WASM.
Comment From: mlkui
This is a good idea! But I think there are also two important features should also be implemented except strings:
- Zero-copy for multi-index dataframe. Currently, multi-index dataframe can not be convert from arrow table with zero copy(zero_copy_only=True), which is a BIGGER problem for big dataframe. You can reset_index() the dataframe, convert it to arrow table, and convert arrow table back to dataframe with zero copy, but after all, you must use call set_index() to the dataframe to get multi-index back, then copy happens.
- Zero-copy for pandas.concat. Arrow table concat can be zero-copy, but when concat two zero-copy dataframe(convert from arrow table), copy happens even pandas COW is turned on. Also, currently, trying to concat two arrow table and then convert the table to dataframe with zero_copy_only=True is also not allowed as the chunknum>1.
Comment From: phofl
@mlkui
Regarding concat: This should already be zero copy:
df = pd.DataFrame({"a": [1, 2, 3]}, dtype="int64[pyarrow]")
df2 = pd.DataFrame({"a": [1, 2, 3]}, dtype="int64[pyarrow]")
x = pd.concat([df, df2])
This creates a new dataframe that has 2 pyarrow chunks.
Can you open a separate issue if this is not what you are looking for?
Comment From: mlkui
@phofl Thanks for your reply. But your example may be too simple. Please view the following codes(pandas 2.0.3 and pyarrow 12.0/ pandas 2.1.0 and pyarrow 13.0):
with pa.memory_map("d:\\1.arrow", 'r') as source1, pa.memory_map("d:\\2.arrow", 'r') as source2, pa.memory_map("d:\\3.arrow", 'r') as source3, pa.memory_map("d:\\4.arrow", 'r') as source4:
c1 = pa.ipc.RecordBatchFileReader(source1).read_all().column("p")
c2 = pa.ipc.RecordBatchFileReader(source2).read_all().column("v")
c3 = pa.ipc.RecordBatchFileReader(source1).read_all().column("p")
c4 = pa.ipc.RecordBatchFileReader(source2).read_all().column("v")
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20))
s1 = c1.to_pandas(zero_copy_only=True)
s2 = c2.to_pandas(zero_copy_only=True)
s3 = c3.to_pandas(zero_copy_only=True)
s4 = c4.to_pandas(zero_copy_only=True)
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20))
dfs = {"p": s1, "v": s2}
df1 = pd.concat(dfs, axis=1, copy=False) #zero-copy
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20))
dfs2 = {"p": s3, "v": s4}
df2 = pd.concat(dfs2, axis=1, copy=False) #zero-copy
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20))
# NOT zero-copy
result_df = pd.concat([df1, df2], axis=0, copy=False)
with pa.memory_map("z1.arrow", 'r') as source1, pa.memory_map("z2.arrow", 'r') as source2:
table1 = pa.ipc.RecordBatchFileReader(source1).read_all()
table2 = pa.ipc.RecordBatchFileReader(source2).read_all()
combined_table = pa.concat_tables([table1, table2])
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20)) #Zero-copy
df1 = table1.to_pandas(zero_copy_only=True)
df2 = table2.to_pandas(zero_copy_only=True)
print("RSS: {}MB".format(pa.total_allocated_bytes() >> 20)) #Zero-copy
#Use pandas to concat two zero-copy dataframes
#But copy happens
result_df = pd.concat([df1, df2], axis=0, copy=False)
#Try to convert the arrow table to pandas directly
#This will raise exception for chunk number is 2
df3 = combined_table.to_pandas(zero_copy_only=True)
# Combining chunks to one will cause copy
combined_table = combined_table.combine_chunks()
Comment From: 0x26res
Beside the build size, there is a portability issue with pyarrow.
pyarrow does not provide wheels for as many environment as numpy.
For environments where pyarrow does not provide wheels, pyarrow has to be installed from source which is not simple.
Comment From: flying-sheep
If this happens, would dtype='string' and dtype='string[pyarrow]' be merged into one implementation?
We’re currently thinking about coercing strings in our library, but hesitating because of the unclear future here.
Comment From: EwoutH
pyarrow does not provide wheels for as many environment as numpy.
The fact that they still don’t have Python 3.12 wheels up is worrisome.
Comment From: h-vetinari
The fact that they still don’t have Python 3.12 wheels up is worrisome.
Arrow is a beast to build, and even harder to fit into a wheel properly (so you get less features, and things like using the slimmed-down libarrow will be harder to pull off).
Conda-forge builds for py312 have been available for a month already though, and are ready in principle to ship pyarrow with a minimal libarrow. That still needs some usability improvements, but it's getting there.
Comment From: musicinmybrain
Without weighing in on whether this is a good idea or a bad one, Fedora Linux already has a libarrow package that provides python3-pyarrow, so I think this shouldn’t be a real problem for us from a packaging perspective.
I’m not saying that Pandas is easy to keep packaged, up to date, and coordinated with its dependencies and reverse dependencies! Just that a hard dependency on PyArrow wouldn’t necessarily make the situation worse for us.
Comment From: ZupoLlask
@h-vetinari Almost there? :-)
Comment From: raulcd
@h-vetinari Almost there? :-)
There is still a lot of work to be done on the wheels side but for conda after the work we did to divide the CPP library, I created this PR which is currently under discussion in order to provide both a pyarrow-base that only depends on libarrow and libparquet and pyarrow which would pull all the Arrow CPP dependencies. Both have been built with support for everything so depending on pyarrow-base and libarrow-dataset would allow the use of pyarrow.dataset, etc.
Comment From: chris-vecchio
Thanks for requesting feedback. I'm not well versed on the technicalities, but I strongly prefer to not require pyarrow as a dependency. It's better imo to let users choose to use PyArrow if they desire. I prefer to use the default NumPy object type or pandas' StringDType without the added complexity of PyArrow.
Comment From: phofl
@flying-sheep
If this happens, would dtype='string' and dtype='string[pyarrow]' be merged into one implementation?
We’re currently thinking about coercing strings in our library, but hesitating because of the unclear future here.
sorry for the slow response, dtype=string will be arrow backed starting from 3.0 or when you activate the infer_string option
Comment From: mynewestgitaccount
From the PDEP:
Starting in pandas 2.2, pandas raises a FutureWarning when PyArrow is not installed in the users environment when pandas is imported. This will ensure that only one warning is raised and users can easily silence it if necessary. This warning will point to the feedback issue.
Is this still planned? It doesn't seem to be occurring in 2.2.0rc0 👀
Comment From: lithomas1
From the PDEP:
Starting in pandas 2.2, pandas raises a FutureWarning when PyArrow is not installed in the users environment when pandas is imported. This will ensure that only one warning is raised and users can easily silence it if necessary. This warning will point to the feedback issue.
Is this still planned? It doesn't seem to be occurring in 2.2.0rc0 👀
I think we are going to add a DeprecationWarning now. (It's not currently in master now, but I'm planning on putting in a warning before the actual release of 2.2).
Comment From: toni-neurosc
Hi, I don't know much about PyArrow overall but when it comes to saving large dataframes as CSV files, I detected that Pandas was being super slow and decided to give PyArrow a try instead, and the difference in performance was astounding, 8x times faster. For a 1GB, all np.float64 dataset:
- pandas_df.to_csv(): Time to save: 45.128990650177 seconds.
- pyarrow.csv.write_csv(): Time to save: 6.1338911056518555 seconds.
I tried stuff like different chucksizes and index=False but it did not help.
However, then I tested PyArrow for reading the exact same dataset and it was 2x slower than Pandas:
- Time to read CSV (pyarrow): 14.770382642745972 seconds.
- Time to read CSV (pandas): 8.440594673156738 seconds.
So, my suggestion I guess would be, to see which tasks are being done more efficiently by PyArrow and incorporate those, and the things that are faster/better in Pandas can stay the same (or maybe PyArrow can incorporate them).
Comment From: phofl
That's exactly what we intend to do. The csv default engine will stay the same for the time being
Comment From: toni-neurosc
That's exactly what we intend to do. The csv default engine will stay the same for the time being
Thanks for your answer Patrick. I missed that there is already an issue open already to add the pyarrow engine to the to_csv method here, so clearly I'm half a year late to the party. Excuse me for rushing to post, should I delete my previous post?
Comment From: mgorny
My initial experience with pandas 2.2.0 + pyarrow is that the test suite crashes CPython on assertions. I will report a bug once I get a clear traceback. This will take some time, as I suppose I need to run them without xdist.
Comment From: mgorny
My initial experience with pandas 2.2.0 + pyarrow is that the test suite crashes CPython on assertions. I will report a bug once I get a clear traceback. This will take some time, as I suppose I need to run them without xdist.
I'm sorry but I can't reproduce anymore. I have had apache-arrow built without all the necessary features, and I've fixed that while testing in serial, so my only guess is that the crashes were due to bad error handling when running tests with xdist. I'm sorry for the noise.
Comment From: willrichmond
pyarrow isn't compatible with the most recent versions of numpy (on 1.26)
pyarrow 0.15.0 would require │ ├─ numpy >=1.16,<1.20.0a0 , which conflicts with any installable versions previously reported;
Comment From: phofl
Pyarrow 15 is the newest release, not 0.15
Comment From: jorenham
NumPy is planning to add support for UTF-8 variable-width string DTypes in NEP 55.
Also, if PyArrow is truly going to be a required required dependency in Pandas 3.0, then I don't see the point of the current DeprecationWarning in pandas 2.2.0. All sane package managers install required dependencies automatically, so users don't need to take any action anyway.
Comment From: jorenham
And as for my opinion: I personally find working with Pandas already complicated enough. So I'm afraid that throwing PyArrow is going to make things worse in that aspect.
In other words:

But like has been said before, the potential benefits haven't been made very clear (yet?), so it's hard to give constructive feedback.
Comment From: jjerphan
@phofl: I think it would be valuable that pandas' maintainers provide reasons for having pandas 3 require PyArrow as a dependency.
Comment From: hagenw
Motivation is briefly outlined in PDEP 10.
pyarrow is already integrated in parts of pandas and it will most likely provide a way to solve the issue that pandas does not only work well with small amounts of data, but also with huge data where it is not the best option at the moment.
Comment From: milosivanovic
Also, if PyArrow is truly going to be a required required dependency in Pandas 3.0, then I don't see the point of the current
DeprecationWarningin pandas 2.2.0. All sane package python managers install required dependencies automatically, so users don't need to take any action anyway.
I have the same question - could someone point me to the justification for why the DeprecationWarning was added? Why do users need to manually install pyarrow now, or be told that a new dependency will be required in a release that isn't even out yet?
Comment From: aman123shampy
thanks
Comment From: jond01
The deprecation warning is ok - but I would like to have a specific pyarrrow "extra" of the pandas package, so that I know my version matches pandas' expectations. Currently, three extras install pyarrow: "feather", "parquet", and "all". It would be nice to add "pyarrow" extra until pandas 3.0 is out, which enables the following:
pip install "pandas[pyarrow]"
Comment From: miraculixx
Thanks for taking feedback from the community.
PDEP 10 lists the following benefits for making pyarrow a required dependency:
Immediate User Benefit 1: pyarrow strings Immediate User Benefit 2: Nested Datatypes Immediate User Benefit 3: Interoperability
From my pov none of these benefits the typical pandas user, unless they already use pyarrow. If they don't they probably don't need the complexity that pyarrow brings with it (as any package of that magnitude does). In this sense I don't feel the rationale given in the PDEP would find a majority in the wider community.
In my opinion, pyarrow should be kept as an optional extra for those users who may need it. This way everyone benefits, from small to large use cases. If pyarrow is made a required dependency primarily large use cases benefit, while all the majority of use cases incur quite a substantial cost (not least due to requiring more disk space but also by making it more difficult to install pandas in some environments).
Comment From: MarcoGorelli
Thanks all for comments!
I can't say anything for certain yet, but I'll start by noting that it looks like this may not be a done deal.
On the numpy side: https://github.com/numpy/numpy/pull/25625/files
we will add implementations for the comparison operators as well as an
addloop that accepts two string arrays,multiplyloops that accept string and integer arrays, anisnanloop, and implementations for thestr_len,isalpha,isdecimal,isdigit,isnumeric,isspace,find,rfind,count,strip,lstrip,rstrip, andreplacestring ufuncs that will be newly available in NumPy 2.0.
and on today's pandas community call, it was mentioned that
if there's a viable alternative to pyarrow strings, then maybe pyarrow doesn't need to be made required
More updates coming in due course
Comment From: js345-ai
Warning (from warnings module): File ", line 1 import pandas as pd DeprecationWarning: Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0), (to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries) but was not found to be installed on your system. If this would cause problems for you, please provide us feedback at https://github.com/pandas-dev/pandas/issues/54466
BUT I GET THE OUTPUT I DONT WANT TO GET THE WARNING MESSAGE I WANT TO IGNORE THAT WARNING MESSAGE
Comment From: adrinjalali
You can install pyarrow to silence the warning. In some other places we're thinking of switching to polars since this warning has come up.
Comment From: MarcoGorelli
Alternatively, if you want to just silence the warning for now:
import warnings
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message=r'\nPyarrow will become',
category=DeprecationWarning,
)
import pandas as pd
I wouldn't normally suggest silencing deprecationwarnings, but given the circumstances this one may be different
Alternatively, just pin pandas < 2.2 for now
Comment From: adrinjalali
@MarcoGorelli I don't see people writing this much code on top of so many of their files/modules/notebooks to silence the warning. It's very annoying, and making CIs fail, where the only solution for those CIs is to add pyarrow to the deps, which itself is huge.
Comment From: js345-ai
You can install
pyarrowto silence the warning. In some other places we're thinking of switching topolarssince this warning has come up.
how to install?
Comment From: MarcoGorelli
like this: https://arrow.apache.org/docs/python/install.html
Comment From: MPhuong124019
Data and DataFrame/Untitled.py:4: DeprecationWarning: Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0), (to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries) but was not found to be installed on your system. If this would cause problems for you, please provide us feedback at https://github.com/pandas-dev/pandas/issues/54466
import pandas as pd
Comment From: adrinjalali
FYI, AWS dependencies of pyarrow are another huge issue:
https://github.com/scikit-learn/scikit-learn/pull/28258#issuecomment-1910294722
Comment From: MarcoGorelli
More updates coming in due course
As promised: https://github.com/pandas-dev/pandas/issues/57073
Comment From: lesteve
Alternatively, if you want to just silence the warning for now:
It is quite unfortunate that the warning message starts with a newline, which makes it hard to target speficically by message with python -W or PYTHONWARNINGS, unless I missed something. For example there is still a warning with this command:
python -W 'ignore:\nPyarrow:DeprecationWarning' -c 'import pandas'
I opened https://github.com/pandas-dev/pandas/issues/57082 about it.
Comment From: Youjin1985
Please remove deprecation warning every time pandas is imported! For example, make it to appear only if some specific file does not exist, and deprecation message should tell user which file to create to suppress the warning.
Comment From: Nowa-Ammerlaan
Note that pyarrow currently does not build with pypy: https://github.com/apache/arrow/issues/19046
I checked just now and indeed found compilation failure:
FAILED: CMakeFiles/lib.dir/lib.cpp.o
/usr/bin/x86_64-pc-linux-gnu-g++ -DARROW_HAVE_RUNTIME_AVX2 -DARROW_HAVE_RUNTIME_AVX512 -DARROW_HAVE_RUNTIME_BMI2 -DARROW_HAVE_RUNTIME_SSE4_2 -DARROW_HAVE_SSE4_2 -Dlib_EXPORTS -I/tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python/pyarrow/src -I/tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/pyarrow/src -isystem /usr/include/pypy3.10 -isystem /usr/lib/pypy3.10/site-packages/numpy/core/include -Wno-noexcept-type -Wno-self-move -Wall -fno-semantic-interposition -msse4.2 -march=native -mtune=native -O3 -pipe -frecord-gcc-switches -flto=16 -fdiagnostics-color=always -march=native -mtune=native -O3 -pipe -frecord-gcc-switches -flto=16 -fno-omit-frame-pointer -Wno-unused-variable -Wno-maybe-uninitialized -O3 -DNDEBUG -O2 -ftree-vectorize -std=c++17 -fPIC -Wno-unused-function -Winvalid-pch -include /tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/CMakeFiles/lib.dir/cmake_pch.hxx -MD -MT CMakeFiles/lib.dir/lib.cpp.o -MF CMakeFiles/lib.dir/lib.cpp.o.d -o CMakeFiles/lib.dir/lib.cpp.o -c /tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/lib.cpp
In file included from /usr/include/pypy3.10/Python.h:55,
from /tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python/pyarrow/src/arrow/python/platform.h:27,
from /tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python/pyarrow/src/arrow/python/pch.h:24,
from /tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/CMakeFiles/lib.dir/cmake_pch.hxx:5,
from <command-line>:
/tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/lib.cpp: In function ‘PyObject* __pyx_pf_7pyarrow_3lib_17SignalStopHandler_6__exit__(__pyx_obj_7pyarrow_3lib_SignalStopHandler*, PyObject*, PyObject*, PyObject*)’:
/tmp/portage/dev-python/pyarrow-14.0.2/work/apache-arrow-14.0.2/python-pypy3/build/temp.linux-x86_64-pypy310/lib.cpp:41444:7: error: ‘PyPyErr_SetInterrupt’ was not declared in this scope; did you mean‘PyErr_SetInterrupt’?
41444 | PyErr_SetInterrupt();
| ^~~~~~~~~~~~~~~~~~
Comment From: stonebig
VirusTotal is not always happy with Pyarrow wheels... example on 15.0 https://www.virustotal.com/gui/file/17d53a9d1b2b5bd7d5e4cd84d018e2a45bc9baaa68f7e6e3ebed45649900ba99
Comment From: migurski
+1 to making it easier to silence the warning. I have no opinion on the pyarrow dependency change but the red warning text in notebook outputs is distracting when they’re meant to be published or shared with colleagues.
Comment From: MarcoGorelli
VirusTotal is not always happy with Pyarrow wheels... example on 15.0 https://www.virustotal.com/gui/file/17d53a9d1b2b5bd7d5e4cd84d018e2a45bc9baaa68f7e6e3ebed45649900ba99
Wasn't aware of that, thanks - is it happy with the current pandas wheels as they are? Is this fixable on the VirusTotal side, and if so, could it be reported to them?
Comment From: stonebig
It's happy with latest pandas wheels
Comment From: glatterf42
Trying to simply install pyarrow to silence the DeprecationWarning causes our tests to fail, e.g.:
FAILED tests/core/test_meta.py::test_run_meta[test_sqlite_mp] - pyarrow.lib.ArrowNotImplementedError: Function 'not_equal' has no kernel matching input types (large_string, double)
I'm not entirely sure why this happens and it only does when pandas[feather] is installed, not with pandas itself. So I guess I'll keep the warning until a much-appreciated migration guide clarifies how to address this issue (if pyarrow ends up being required).
Comment From: phofl
@glatterf42 could you copy paste the test content?
Comment From: glatterf42
Sure :)
There is more than one test, but they all boil down to the same line:
Full traceback of one test
______________________________________________________ test_run_meta[test_sqlite_mp] _______________________________________________________
test_mp = <ixmp4.core.platform.Platform object at 0x7ffae19bd150>, request = <FixtureRequest for <Function test_run_meta[test_sqlite_mp]>>
@all_platforms
def test_run_meta(test_mp, request):
test_mp = request.getfixturevalue(test_mp)
run1 = test_mp.runs.create("Model 1", "Scenario 1")
run1.set_as_default()
# set and update different types of meta indicators
> run1.meta = {"mint": 13, "mfloat": 0.0, "mstr": "foo"}
tests/core/test_meta.py:18:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
ixmp4/core/run.py:52: in meta
self._meta._set(meta)
ixmp4/core/run.py:122: in _set
self.backend.meta.bulk_upsert(df)
ixmp4/core/decorators.py:15: in wrapper
return checked_func(*args, **kwargs)
.venv/lib/python3.10/site-packages/pandera/decorators.py:754: in _wrapper
out = wrapped_(*validated_pos.values(), **validated_kwd)
ixmp4/data/auth/decorators.py:37: in guarded_func
return func(self, *args, **kwargs)
ixmp4/data/db/meta/repository.py:194: in bulk_upsert
super().bulk_upsert(type_df)
ixmp4/data/db/base.py:339: in bulk_upsert
self.bulk_upsert_chunk(df)
ixmp4/data/db/base.py:357: in bulk_upsert_chunk
cond.append(df[col] != df[updated_col])
.venv/lib/python3.10/site-packages/pandas/core/ops/common.py:76: in new_method
return method(self, other)
.venv/lib/python3.10/site-packages/pandas/core/arraylike.py:44: in __ne__
return self._cmp_method(other, operator.ne)
.venv/lib/python3.10/site-packages/pandas/core/series.py:6099: in _cmp_method
res_values = ops.comparison_op(lvalues, rvalues, op)
.venv/lib/python3.10/site-packages/pandas/core/ops/array_ops.py:330: in comparison_op
res_values = op(lvalues, rvalues)
.venv/lib/python3.10/site-packages/pandas/core/ops/common.py:76: in new_method
return method(self, other)
.venv/lib/python3.10/site-packages/pandas/core/arraylike.py:44: in __ne__
return self._cmp_method(other, operator.ne)
.venv/lib/python3.10/site-packages/pandas/core/arrays/arrow/array.py:704: in _cmp_method
result = pc_func(self._pa_array, self._box_pa(other))
.venv/lib/python3.10/site-packages/pyarrow/compute.py:246: in wrapper
return func.call(args, None, memory_pool)
pyarrow/_compute.pyx:385: in pyarrow._compute.Function.call
???
pyarrow/error.pxi:154: in pyarrow.lib.pyarrow_internal_check_status
???
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
> ???
E pyarrow.lib.ArrowNotImplementedError: Function 'not_equal' has no kernel matching input types (large_string, double)
pyarrow/error.pxi:91: ArrowNotImplementedError
Verbose description
The test is defined [here](https://github.com/iiasa/ixmp4/blob/2b6f5eff52d2a36904264126f619b21438db7df1/tests/core/test_meta.py#L12-L18) with the fixtures coming from [here](https://github.com/iiasa/ixmp4/blob/2b6f5eff52d2a36904264126f619b21438db7df1/tests/utils.py#L26-L34) and [here](https://github.com/iiasa/ixmp4/blob/2b6f5eff52d2a36904264126f619b21438db7df1/tests/conftest.py#L112-L137). The line in question is in [ixmp4/data/db/base.py](https://github.com/iiasa/ixmp4/blob/2b6f5eff52d2a36904264126f619b21438db7df1/ixmp4/data/db/base.py#L344-L357) in the `bulk_upsert_chunk()` function. It combines a `pandas.DataFrame` from an existing and to-be-added one and is then trying to figure out which of the columns was updated. There's a [limited set of columns](https://github.com/iiasa/ixmp4/blob/2b6f5eff52d2a36904264126f619b21438db7df1/ixmp4/data/db/meta/model.py#L30-L36) that may be updated. During the combination process, the to-be-added columns receive a `_y` suffix to be distinguishable. If such an updatable column is found the the combined dataframe, a bool should be added to a list if it's truly different from the existing one. And precisely this condition check, `df[col] != df[updated_col]`, fails when pyarrow is present.Comment From: ItsSatviK13
Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0), (to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries) but was not found to be installed on your system. If this would cause problems for you,
I am getting this error after trying to import pandas
Comment From: jagoodhand
A little late to the party, but wanted to add an objection from me due to the hugely increased installation size from PyArrow.
Primarily, this relates to AWS Lambda. I use Pandas significantly in the AWS Lambda environment, and this would cause headaches. I think it is just possible to get Pandas and PyArrow into a Lambda package, but means there is very little room for anything else in there.
I tried to experiment with this recently, and couldn't get it smaller enough to the point I could have the other stuff in the package that I wanted. I believe the work-around is to use containers with Lambda instead, but this requires a whole shift in deployment methodology for a single package dependency. There would be a further trade-off from the increased start times due to having to load a significantly larger package (or container).
I realise that this environment-specific objection may not have much weight, but my other comment would be:
Pandas is generally one of the first, approachable ways for new users to start playing around with data, and data-science tools. Specifically, a tool that can then be scaled towards more advanced usage. My experience has been that installing PyArrow can be a complex process, filled with pit-holes that can make what is currently a relatively simple installation process, a real headache. I think that this change could really harm the approachability of Pandas, and put off future users.
I would strongly request that PyArrow remain an optional dependency that advanced users (who by definition would be able to handle any installation requirements), can install and configure if necessary.
Comment From: alippai
Next to pyarrow and numpy, related (recent) literature https://pola.rs/posts/polars-string-type/
Comment From: putulsaini
whenever i am using pandas..this pyArrow showing and everytime i'm getting problem of using pandas, everytime i'm running pandas in python.please help
Comment From: Rich5
Sorry if I'm missing this somewhere, but is there a way to silence this warning?
Comment From: jorisvandenbossche
is there a way to silence this warning?
Install pyarrow!
Or if you still want to avoid doing that for now, you can silence the warning with the stdlib warnings.filterwarning module:
>>> import warnings
>>> warnings.filterwarnings("ignore", "\nPyarrow", DeprecationWarning)
>>> import pandas
(unfortunately it currently doesn't work as -W command line argument or pytest config option, see https://github.com/pandas-dev/pandas/issues/57082)
Comment From: Rich5
Perfect! Thanks @jorisvandenbossche
Comment From: Ygrik1308
Warning (from warnings module): File "C:/Git/Work/Pyton/Pandas_ecel.py", line 1 import pandas as pd DeprecationWarning: Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0), (to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries) but was not found to be installed on your system. If this would cause problems for you, please provide us feedback at https://github.com/pandas-dev/pandas/issues/54466
Comment From: ZupoLlask
@jagoodhand I may have got it wrong but, from my understanding, by the time PyArrow becomes a mandatory dependency of Pandas 3.0.0, that dependency will be a new package that doesn't exists today basically around libarrow called pyarrow-minimal, that will be much much smaller (in size) and portable (in terms of CPU architectures, that may narrow the gap to Numpy current availability in that matter) and will be released with PyArrow 15.
@h-vetinari & devs, please correct me if I'm wrong...
Comment From: jagoodhand
@ZupoLlask - if it addresses the two issues I mentioned:
- Package Size
- Installation complexity / compatibility / portability i.e. easily being able to install on different platforms
Then my objections aren't objections any more, but it doesn't sound like this is the case. Would be good to have more detail or confirmation on what this would look like though.
Comment From: raulcd
by the time PyArrow becomes a mandatory dependency of Pandas 3.0.0, that dependency will be a new package that doesn't exists today basically around
libarrowcalledpyarrow-minimal, that will be much much smaller (in size) and portable (in terms of CPU architectures, that may narrow the gap to Numpy current availability in that matter) and will be released with PyArrow 15.
This is not exactly the case. Let me expand a little on what is happening at the moment:
The Arrow team did release Arrow and pyarrow 15.0.0 a couple of weeks ago. There is some ongoing work and efforts from the Arrow community in reducing the footprint of minimal builds of Arrow. At the moment there is an opened PR on the conda feedstock for Arrow, which I am working on, to be able to have several different installations for pyarrow. Based on review and design discussions it seems there will be pyarrow-core, pyarrow and pyarrow-all with different subsets of features and sizes.
There is no change about the current CPU architectures supported but please if your system is not supported you can always open an issue or a feature request to the Arrow repository.
We still have to plan and do the work for published wheels on PyPI but this still requires planning and contributors to actively work on. Some issues that are related: https://github.com/apache/arrow/issues/24688
Comment From: amol-
We still have to plan and do the work for published wheels on PyPI but this still requires planning and contributors to actively work on. Some issues that are related: apache/arrow#24688
For the purpose of being able to package PyArrow in smaller wheels, I had created https://github.com/amol-/consolidatewheels but it would require some real world testing. https://github.com/amol-/wheeldeps was created as an example, but the more testing we can get, the faster we will be able to split pyarrow wheels
Comment From: CotaZ
Bueno sí algunos le preocupa la ram, lo optimo son 16 gb para hacer trabajos solidos, pero bueno cada uno ve su alcance con su cliente.
Comment From: max-radin
This is not feedback on the decision to include pyarrow as a dependency, but rather on the usage of deprecation warnings to solicit feedback. Raising deprecation warnings (especially in the main __init__.py) adds a lot of noise to downstream projects. It also creates a development burden for packages whose CI treats warnings as errors (see for example https://github.com/bokeh/bokeh/issues/13656 and https://github.com/zapatacomputing/orquestra-cirq/pull/53). Ideally deprecation warnings would be reserved for changes to the pandas public API and be raised only in the code paths affected by the change.
Comment From: mynewestgitaccount
This is not feedback on the decision to include pyarrow as a dependency, but rather on the usage of deprecation warnings to solicit feedback. [...] Ideally deprecation warnings would be reserved for changes to the pandas public API and be raised only in the code paths affected by the change.
Even by your own logic, including a warning was the right choice. The inclusion of PyArrow will come with a major change to the pandas public API: "Starting in pandas 3.0, the default type inferred for string data will be ArrowDtype with pyarrow.string instead of object." (quoted from the PDEP)
However, I think a FutureWarning, as originally was proposed in the PDEP, would have made more sense than the DeprecationWarning that was implemented.
Regardless, if the deprecation warning creates issues for you, you can just install PyArrow to make it go away. If installing PyArrow would create issues for you, that's what this issue is for. Considering the change can cause CI failures, the warning preemptively causing CI failures seems like the lesser of two bad options.
Bias disclosure: I'm impacted negatively by the upcoming change.
Comment From: MohamedElashri
I want to add that there are some versions of Linux distributions which are either extended support or LTS that would be very hard to install pyarrow as they don't get packaged like CentOS 7 and ubuntu 18.04 LTS
Comment From: Alexey174
the first thought that arose was to replace pandas with another similar tool
Comment From: BMaxV
I dislike the process here, and I don't mean the dep warning.
- Why are you doing this? What are the pros and cons? Surely you have discussed doing this and there are pros and cons for this. Please link to that discussion. ("If it's difficult to explain, it's a bad idea")
- Why is increasing the complexity of your package the default and correct way of providing this functionality?
I appreciate the message and asking for feedback, but it went out to everyone and that will include people like me who have no idea what's going on. It is generally your business how you run your project (Thank you for your work and software), but if you do want feedback and if you do want to be inclusive, please think about how you are onboarding to this issue.
Generally, complexity is bad and changing things in bad, because there is the risk of new errors. So you are starting at a negative score in my book and this whole thing would require a significant gain and not just a neutral tradeoff between increased size and some performance.
(I think there is a general blindness in this respect from package maintainers, because you are working with this every day and you think some increase in complexity is acceptable for [reasons] and this continues for decades and then you have a bloated mess.)
Does it have to be done this way, can't you create a new package that uses the advantages of both packages and overrides the original function? Then if people want to they can use both and it leaves the original thing untouched. Maybe put a note into the docs pointing to the optimization.
Comment From: asishm-wk
- Surely you have discussed doing this and there are pros and cons for this. Please link to that discussion.
The discussion is linked in the PDEP itself - https://github.com/pandas-dev/pandas/pull/52711
Comment From: jfaccioni-asimov
I know this isn't super relevant to the discussion, but I want to throw this out here anyway. Sometimes, even a harmless change like displaying a DeprecationWarning can have undesired repercussions.
I teach Python courses for programming beginners, and since the 2.2.0 release I've received many questions and messages from students confused by the warning. They are left wondering if they installed pandas correctly, if they need to install something called "arrow", or whether they can continue the course at all.
Yes, I know the students should eventually get used to warning messages, and this discussion is definitely relevant to the Data Science community. But realistically, 99% of the people to ever import pandas as pd will never come remotely close to it.
As stated previously, if pyarrow ever becomes a dependency of pandas (disregarding whether that's a good or a bad thing), the vast majority of users shouldn't even notice any difference. Everything should "just work" when they type pip install pandas. As a result, I find the decision to display a DeprecationWarning to the entire user base upon importing pandas unfortunate.
Comment From: ZupoLlask
Well, I think all these contributions for the discussion end up being useful for the community as a whole.
Maybe developers may consider another approach regarding communication of deprecation: - including major pending deprecation warnings in the changelog / release notes for every new release; - creating some kind of verbose deprecation mode so interested developers can check and test their code future compatibility, while disabling this level of DeprecationWarning verbosity disabled for the regular users.
There is no perfect solution to deal with the current situation, but I'm positive PyArrow will bring very good benefits for Pandas in the future! 🙂
Comment From: wshanks
I want to follow up on https://github.com/pandas-dev/pandas/issues/54466#issuecomment-1906654486 from above about a pyarrow extra. The message just says that you need to have "Pyarrow". It would be better if it suggested installing pandas[feather] (or pandas[pyarrow] if feather does not just mean pyarrow). Adding transitive dependencies to a project''s dependency list should be avoided if possible. From the warning message, it seems that the suggested solution is to add pyarrow to your dependency list.
Also, since the warning directs users to this issue, it would be nice if the issue description were edited to include suggestions on how to avoid it -- both whether to add pyarrow to your dependencies or use pandas[feather] and also the filterwarnings solution.
Comment From: jamesbraza
I agree @wshanks, I opened https://github.com/pandas-dev/pandas/pull/57284 to introduce that extra. If people like it, I can add a docs entry for Pandas 2.2.1
Comment From: gipert
This change is making a mess in CI jobs. Suppressing the warning as suggested in https://github.com/pandas-dev/pandas/issues/54466#issuecomment-1919988166 is not a viable solution and I could not even find a robust way to code "exclude Pandas versions >=2.2 AND < 3" as a requirement specifier in pyproject.toml.
Comment From: max-radin
This is not feedback on the decision to include pyarrow as a dependency, but rather on the usage of deprecation warnings to solicit feedback. [...] Ideally deprecation warnings would be reserved for changes to the pandas public API and be raised only in the code paths affected by the change.
Even by your own logic, including a warning was the right choice. The inclusion of PyArrow will come with a major change to the pandas public API: "Starting in pandas 3.0, the default type inferred for string data will be ArrowDtype with pyarrow.string instead of object." (quoted from the PDEP)
However, I think a FutureWarning, as originally was proposed in the PDEP, would have made more sense than the DeprecationWarning that was implemented.
Regardless, if the deprecation warning creates issues for you, you can just install PyArrow to make it go away. If installing PyArrow would create issues for you, that's what this issue is for. Considering the change can cause CI failures, the warning preemptively causing CI failures seems like the lesser of two bad options.
Bias disclosure: I'm impacted negatively by the upcoming change.
I agree that including a warning for string type inference makes sense. However I'm not sure that the main __init__.py is the best place for this warning because it creates noise for projects that do not depend on string type inference and therefore may not be affected by the change.
Also I understand that the warning can be suppressed by installing PyArrow. The point is that any approach to suppressing the warning requires a certain amount of knowledge and effort. I'm thinking for example of the questions that @jfaccioni-asimov gets from confused students.
Comment From: hagenw
When switching to pyarrow for the string dtype, it would be good if some of the existing performance issues with the string dtype are addresses beforehand. Currently (pandas 2.2.0), string[pyarrow] is the slowest solution for some tasks:
import pandas as pd
import timeit
points = 1000000
data = [f"data-{n}" for n in range(points)]
for dtype in ["object", "string", "string[pyarrow]"]:
index = pd.Index([f"index-{n}" for n in range(points)], dtype=dtype)
df = pd.DataFrame(data, index=index, dtype=dtype)
print(dtype)
%timeit df.loc['index-2000']
which returns
object
9.78 µs ± 18.9 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
string
15.7 µs ± 36.5 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
string[pyarrow]
17.6 µs ± 66.6 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Comment From: MarcSkovMadsen
I'm a contributor to Panel by HoloViz.
Pandas is used extensively in the HoloViz ecosystem. Its a hard requirement of Panel.
Usage in pyodide and pyscript has really benefitted us a lot. It has made our docs interactive and enabled our users to share live Python GUI applications in the browser without having to fund and manage a server.
As far as I can see Pyarrow does not work with pyodide. I.e. Pandas would no longer work in Pyodide? I.e. Panel would no longer work in Pyodide?
Thinking outside of HoloViz Panel I believe that making Pandas unusable in Pyodide or increasing the download time risks making all gains of Python in the browser with Pyodide and Pyscript unusable.
Thanks for asking for feedback. Thanks for Pandas.
Comment From: lesteve
There is ongoing work about Pyarrow support in Pyodide, for example see https://github.com/pyodide/pyodide/issues/2933. If I try to use my crystal ball, my guess is that pandas developers have this in mind. Also even in the case of pandas 3.0 go out, require Pyarrow and Pyarrow support is still not there in Pyodide, you will always be able to use older pandas versions in Pyodide so unless you need a pandas 3.0 feature, you will be fine.
Comment From: MarcSkovMadsen
Thx @lesteve .
- Panel might not need the never version of Pandas. But users will also be using Pandas when they develop their data driven applications using Pandas and Panel. And they would expect to be on a recent version of Pandas.
- And the package size of pyarrow would also increase down load time in pyodide considerably.
These issues are not limited to Panel. They will limit entire PyData ecosystem using pyodide to make their docs interactive without spending huge amounts on servers. They will also limit Streamlit (Stlite), Gradio (Gradiolite), Jupyterlite, PyScript etc. running in the browser. Which is where the next 10 million Python users are expected to come from.
Comment From: wirable23
Are there 3 distinct arrow string types in pandas?
- "string[pyarrow_numpy]"
- "string[pyarrow]"
- pd.ArrowDtype(pa.string())
Is the default going to be string[pyarrow_numpy]? What are the differences between the 3 string datatypes and when should 1 be used over the other? Do they all perform the same because they use the same arrow memory layout and compute kernels?
Comment From: mjugl
is there a way to silence this warning?
You can do it with the stdlib
warnings.filterwarningmodule:```python
import warnings warnings.filterwarnings("ignore", "\nPyarrow", DeprecationWarning) import pandas ```
(unfortunately it currently doesn't work as
-Wcommand line argument or pytest config option, see #57082)
If you're using pytest and the warnings are polluting your CI pipelines, you can ignore this warning by editing your pytest.ini like so:
[pytest]
filterwarnings =
ignore:\nPyarrow:DeprecationWarning
See pytest docs on controlling warnings.
Comment From: kanhaiya0318
Debian/Ubuntu have system packages for pandas but not pyarrow, which would no longer be possible. (System packages are not allowed to depend on non-system packages.)
I don't know whether creating a system package of pyarrow is possible with reasonable effort, or whether this would make the system pandas packages impossible to update (and eventually require their removal when old pandas was no longer compatible with current Python/numpy).
Comment From: dwivedi281
is there a way to silence this warning?
You can do it with the stdlib
warnings.filterwarningmodule:```python
import warnings warnings.filterwarnings("ignore", "\nPyarrow", DeprecationWarning) import pandas ```
(unfortunately it currently doesn't work as
-Wcommand line argument or pytest config option, see #57082)
I want to add that there are some versions of Linux distributions which are either extended support or LTS that would be very hard to install pyarrow as they don't get packaged like CentOS 7 and ubuntu 18.04 LTS
Comment From: dwivedi281
I want to add that there are some versions of Linux distributions which are either extended support or LTS that would be very hard to install pyarrow as they don't get packaged like CentOS 7 and ubuntu 18.04 LTS
Comment From: dwivedi281
I want to add that there are some versions of Linux distributions which are either extended support or LTS that would be very hard to install pyarrow as they don't get packaged like CentOS 7 and ubuntu 18.04 LTS
Comment From: dwivedi281
I want to add that there are some versions of Linux distributions which are either extended support or LTS that would be very hard to install pyarrow as they don't get packaged like CentOS 7 and ubuntu 18.04 LTS
Comment From: mgorny
FYI, I've added pyarrow dep on 2024-01-20 to the Gentoo ebuild and requested testing on the architectures we support. So far it's looking grim — no success on ARM, AArch64, PowerPC, X86. I feel like I'm now being made responsible for fixing Arrow, that doesn't seem to be very portable in itself.
Comment From: h-vetinari
Arrow, that doesn't seem to be very portable in itself.
We build arrow and run the test suite successfully on all the mentioned architecture in conda-forge, though admittedly the stack of dependencies is pretty involved (grpc, protobuf, the major cloud SDKs, etc.). Feel free to check out our recipe if you need some inspiration, or open an issue on the feedstock if you have some questions.
Comment From: enzbus
Dear maintainers and core devs,
thank you for making Pandas available to the community. Since you ask for feedback, here's my humble opinion
As a longtime user and developer of open-source libraries which depend on Pandas, I mostly deal with (possibly) large Dataframes with homogeneous dtype (np.float64), and I treat them (for the most part) as wrapper around the corresponding Numpy 2-dimensional Arrays. The reason I use Pandas Dataframes as opposed to plain Numpy Arrays is that I find Pandas indexing capabilities to be its "killer" feature, it's much safer from my point of view to keep track of indexing in Pandas rather than Numpy, especially when considering Datetime indexes or multi-indexes. The same applies to Series and Numpy 1-dimensional Arrays.
I have no objections to using Arrow as back-end to store string, object dtypes, or in general non-homogeneous dtype Dataframes.
I would like, however, to hear whether you plan to switch away from Numpy as one of the core back-ends (in my usecases, the most important one). This is relevant for various reasons, including memory management. It would be great to know if in the future one will have to worry that manipulating large 2-dimensional Numpy Arrays of floats by casting them as Dataframes will involve a conversion into Arrow, and back to Numpy (if then I want them back as such). That would be very problematic, since it involves a whole new layer of complexity.
Thanks, Enzo
Comment From: admajaus
Pyarrow is a HUGE library - it's over 70MB. If it's part of your deployment package to AWS lambda or any cloud computing service with size restrictions and you already have numpy, pandas, and a plotting library, this will easily put your over size restrictions, even if you move your deployment package into cloud storage(s3, for example). If pyarrow will become a pandas dependencey, you need to parse out from the overall package what is actually needed vs. making people download the whole, massive library.
Comment From: mgorny
We build arrow and run the test suite successfully on all the mentioned architecture in conda-forge, though admittedly the stack of dependencies is pretty involved (grpc, protobuf, the major cloud SDKs, etc.). Feel free to check out our recipe if you need some inspiration, or open an issue on the feedstock if you have some questions.
Does that include 32-bit arches? The errors I'm getting from pyarrow's test suite suggest things may not work at all:
FAILED tests/interchange/test_conversion.py::test_pandas_roundtrip_string - OverflowError: Python int too large to convert to C ssize_t
FAILED tests/interchange/test_conversion.py::test_pandas_roundtrip_large_string - OverflowError: Python int too large to convert to C ssize_t
FAILED tests/interchange/test_conversion.py::test_pandas_roundtrip_string_with_missing - OverflowError: Python int too large to convert to C ssize_t
FAILED tests/interchange/test_conversion.py::test_pandas_roundtrip_categorical - OverflowError: Python int too large to convert to C ssize_t
FAILED tests/interchange/test_conversion.py::test_empty_dataframe - OverflowError: Python int too large to convert to C ssize_t
That said, I need to figure out if it's a problem with pyarrow or pandas first, before reporting this.
Comment From: h-vetinari
Does that include 32-bit arches?
Nope, 64bit only, sorry. We already dropped support for 32bit years ago, and it's IMO very badly tested across the ecosystem, so I expect significant bitrot to have set in.
Comment From: wimglenn
This is a strange use of DeprecationWarning. There is nothing being deprecated, and I would expect dependency changes in the next major release anyway. Using a warning for this informational message causes problems in environments when user chooses to escalate warnings into errors.
It's tangential to the question of growing a pyarrow dependency, but I'm not sure that issuing a warning was the best way to collect user feedback.
Comment From: ZupoLlask
@admajaus It has been explained above that future mandatory pyarrow dependency will not imply current pyarrow package but the new pyarrow-core (libarrow only) or pyarrow-base (libarrow and libparquet only), that will be published for the first time in a matter of weeks.
https://github.com/conda-forge/arrow-cpp-feedstock/pull/1255
This has nothing to do with a size of 70MB.
Comment From: bersbersbers
@admajaus It has been explained above that future mandatory pyarrow dependency will not imply current pyarrow package
I think it had not (at least not explicitly), but assuming that is true, thanks for clarifying!
Comment From: ghost
@admajaus It has been explained above that future mandatory
pyarrowdependency will not imply currentpyarrowpackage but the newpyarrow-core(libarrowonly) orpyarrow-base(libarrowandlibparquetonly), that will be published for the first time in a matter of weeks.conda-forge/arrow-cpp-feedstock#1255
This has nothing to do with a size of 70MB.
My understanding is this is only for conda; how about PyPI wheels?
Comment From: ZupoLlask
@zhizheng1 Your doubt is absolutely reasonable and I don't have an answer for you. However, this is the way I see it: as the developers working in this change for conda are Arrow developers, it wouldn't make sense that this change isn't also coming to PyPI even if it lands a bit later.
I may be wrong but as long as the (hard) work is done for conda, it will be a matter of time (way before Pandas 3.0 release) to have the new wheels available in PyPI.
Comment From: combiz
Preference would be to add the PyArrow deps as extras_require with users requiring the new functionality installing pandas with, e.g. pip install pandas[full]
Comment From: bersbersbers
@zhizheng1 Your doubt is absolutely reasonable [...] I don't have an answer for you [...] the way I see it [...] it wouldn't make sense [...] I may be wrong
That's a lot of uncertainty regarding your earlier statement of
future mandatory pyarrow dependency will not imply current pyarrow package
Comment From: ZupoLlask
@bersbersbers As far as I know, there's no fixed release month settled for Pandas 3.0. From what I see in several repositories, there's several people working everyday to bring a libarrow-only pyarrow-core to light.
Apart from that, this is easily one of the most commented issues in this repository. There's no evidence that these concerns won't be addressed properly.
Shall we give some time to let the dust settle a bit? :-)
Yes, I admit that those quotes seem inconsistent, but I see there are PR that are going to be merged soon at Arrow repository to enable this sort of split... only for conda? It makes no sense. There's been some comments regarding PyPI but as that's not what is currently being worked on, I guess that people is trying to first focus in conda and PyPI will come next.
Comment From: Drewskie75
This is an issue to collect feedback on the decision to make PyArrow a required dependency and to infer strings as PyArrow backed strings by default.
The background for this decision can be found here: https://pandas.pydata.org/pdeps/0010-required-pyarrow-dependency.html
If you would like to filter this warning without installing pyarrow at this time, please view this comment: #54466 (comment)
surprising but nice update coming soon
Comment From: mroeschke
I'm going try to summarize/respond to prevailing themes and some questions in this thread as of 2024-02-15:
PyArrow as a required dependency in 3.0
I think the prevailing concerns so far (some of which are mentioned in the Drawback section of the proposal) are:
- I (may/will not benefit) from strings being backed by PyArrow by default in pandas 3.0 and therefore find PyArrow being required as unnecessary.
- I am running pandas on [platform/environment] where including PyArrow may/will become onerous to include (too large to install/doesn't work).
While the plan as of now is to still move forward with PyArrow as a required dependency in pandas 3.0, which is tentatively scheduled for release in April 2024, I think the volume of response has spurred serious reconsideration of this decision in https://github.com/pandas-dev/pandas/issues/57073
The (annoying) DeprecationWarning upon importing pandas that probably led you here
The core team is currently voting in https://github.com/pandas-dev/pandas/issues/57424 on whether to remove this warning in the pandas 2.2.1 which is schedule to be released next week (the week of 2024-02-19)
Including a way to install pandas and get pyarrow automatically
At least when installing with pip, yes, we will add an extra so that pip users can use pip install pandas[pyarrow]
I would like, however, to hear whether you plan to switch away from Numpy as one of the core back-ends
@enzbus Numpy will probably never be dropped as a back-end, but like the current proposal, Numpy may not be the default back end for some types (strings, list, dict, decimal, etc.)
Are there 3 distinct arrow string types in pandas?
@wirable23 I would say "flavors" but (unfortunately) yes, due to legacy reasons/efforts to maintain backward compatibility
-
"string[pyarrow]"akapandas.StringDtype("pyarrow"): introduced in pandas 1.3. Usespd.NAas it's missing value. -
pandas.ArrowDtype(pa.string()): Introduced in pandas 1.5 as a consequence ofpandas.ArrowDtypesupporting all Arrow types. Usespd.NAas it's missing value. -
"string[pyarrow_numpy]"akapandas.StringDtype("pyarrow_numpy"): Introduced in pandas 2.1. Usesnp.nanas its missing value to be more backward compatible with existing default NumPy dtypes and is the proposed default string type in pandas 3.0
Comment From: susmitpy
Adding pyarrow as a required dependency will cause the size of pandas library to explode. This is very crucial for serverless functions such as aws lambda functions , gcp cloud functions etc. As not only does it will have an impact of loading time but also these have size limits for the files you can attach. For example, the hard limit for a aws lambda layer is 250 MB. From experience, whenever I need to deal with parquet files, I use fast parquet instead of pyarrow due to the huge difference in sizes.
Comment From: Sai123-prathyu
Thankyou its working
Comment From: dwgillies
I too was hoping to use pandas in an embedded AWS lambda function. If the size explodes, this will be a huge overhead. I am currently using about 0.004% of the pandas library. From the looks of this discussion, my usage will not change nor will I ever need pyarrow but I will now be using 0.0015% of the pandas library, and paying dearly for it, probably by abandoning this bloated software.
I have found and verified that the deprecation warning can be suppressed with this : https://github.com/pandas-dev/pandas/issues/54466#issuecomment-1919988166
Does anyone have a procedure for installing pyarrow in cygwin?
Note: straightforward installation does not work.
cygwin$ python3.9 -m pip install pyarrow
...
-- Generator: Unix Makefiles
-- Build output directory: /tmp/pip-install-obx0lyoa/pyarrow_5ca48afb32b3451db0badc556c1c74fc/build/temp.cygwin-3.5.0-x86_64-cpython-39/release
-- Found Python3: /usr/bin/python3.9.exe (found version "3.9.16") found components: Interpreter Development.Module NumPy
-- Found Python3Alt: /usr/bin/python3.9.exe
CMake Error at CMakeLists.txt:268 (find_package):
By not providing "FindArrow.cmake" in CMAKE_MODULE_PATH this project has
asked CMake to find a package configuration file provided by "Arrow", but
CMake did not find one.
Could not find a package configuration file provided by "Arrow" with any of
the following names:
ArrowConfig.cmake
arrow-config.cmake
Add the installation prefix of "Arrow" to CMAKE_PREFIX_PATH or set
"Arrow_DIR" to a directory containing one of the above files. If "Arrow"
provides a separate development package or SDK, be sure it has been
installed.
-- Configuring incomplete, errors occurred!
See also "/tmp/pip-install-obx0lyoa/pyarrow_5ca48afb32b3451db0badc556c1c74fc/build/temp.cygwin-3.5.0-x86_64-cpython-39/CMakeFiles/CMakeOutput.log".
error: command '/usr/bin/cmake' failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for pyarrow
Failed to build pyarrow
ERROR: Could not build wheels for pyarrow, which is required to install pyproject.toml-based projects
Comment From: yangrudan
my code is simple:
"""
Copyright (c) Cookie Yang. All right reserved.
"""
from __future__ import print_function, division
import os
import torch
import pandas as pd
#用于更容易地进行csv解析
from skimage import io, transform
#用于图像的IO和变换
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
plt.ion()
# interactive mode
when I run srcipt:
python pic_io_csv.py
/home/yangrudan/workspace/demo/pytorch_learn/pic_io_csv.py:7: DeprecationWarning: Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0), (to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries) but was not found to be installed on your system. If this would cause problems for you
Comment From: maksym-petrenko
What is the minimum version of PyArrow that will work with pandas?
Comment From: jsolbrig
@dwgillies I don't use Cygwin so I can only help a little with your installation issue. Pyarrow doesn't provide a wheel for your OS and architecture. So, pip is trying to build a wheel from source. In order to build form source, pyarrow requires that you have libarrow installed. If you install libarrow, then try to pip install again, it might work.
Comment From: sahilfatima
Importing model
Comment From: Soft-Buddy
I don't consider this a good decision, a huge increment in the installation size will be there :(
Comment From: miraculixx
@dwgillies https://github.com/pandas-dev/pandas/issues/54466#issuecomment-1955241211
Does anyone have a procedure for installing pyarrow in cygwin? Note: straightforward installation does not work.
That's a great question - many companies rely on Python + Pandas running in cygwin, mingw (through git-bash) and Msys in their Windows work PCs. It is often the best way to have a useful Python dev env in a corporate environment.
Will Pandas+PyArrow be supported in these environments? If not there is a high risk of lots of outdated installations bc these environments are rather sticky once deployed, and there is no easy way to upgrade to Linux or WSL.
Comment From: Soft-Buddy
@dwgillies #54466 (comment)
Does anyone have a procedure for installing pyarrow in cygwin? Note: straightforward installation does not work.
That's a great question - many companies rely on Python + Pandas running in cygwin, mingw (through git-bash) and Msys in their Windows work PCs. It is often the best way to have a useful Python dev env in a corporate environment.
Will Pandas+PyArrow be supported in these environments? If not there is a high risk of lots of outdated installations bc these environments are rather sticky once deployed, and there is no easy way to upgrade to Linux or WSL.
Our issues kinda match buddy. I use pandas in my android app which ships a cross compiled copy of python and of pandas compiled using crossenv. PyArrow's installation doesn't work there either... And triggers some weird errors
Comment From: jkmackie
My general concern with the mandatory PyArrow dependency is chasing competing standards and dependency issues like bugs.
Kindly recall PDEP 10 lists three key benefits of pyarrow: (1) better pyarrow string memory/speed; (2) nested datatypes; and (3) interoperability.
PDEP Point 1 - Pandas 2.2.0 Performance To make this less abstract, below are Pandas performance stats based on the 1brc challenge of aggregating 1 billion rows of city temperatures as fast as possible.
1brc INPUT - 1 billion rows
2 columns: city and temperature
OUTPUT - Temp mean/min/max by city
Metrics
Memory These metrics use the default DataFrame format: city is 'object' and temperature is 'float64'.
Turns out the city column 'object' format hogs :pig: 90% of the 'deep' memory usage ⵜ. This is indeed an issue! The last 10% of memory is temperatures. Downcasting to 'float32' halves memory for the temperature column.
ⵜ Memory Footnote:
There's a mismatch between dataframe 'deep' memory usage (69GB) and the PC RAM increase I saw in Task Manager (about 23-24 GB) during pd.read_parquet(). My system memory is 64GB. Hard to believe 2GB memory compression accounts for the discrepancy.
Speed Reading from parquet is 2.5 times as fast as reading from csv and takes one-fifth the space (snappy compression). Mean/min/max aggregation time was reasonable at under one minute.
PDEP Point 2 - Nesting
The PDEP 10 nested datatype example saves [{'a': 1, 'b': 2}, {'a': 2, 'b': 99}] to a Series rather than a DataFrame. The pyarrow benefit is saving an unknown nested structure as speed/memory efficient strings.
The existing alternative is use pd.json_normalize() or pd.DataFrame() to load the example into a DataFrame with a column for eack key. Foreknowledge of the format is required. Then downcast numeric columns with pd.to_numeric(df[mycol], downcast=<'integer', 'signed', 'unsigned', or 'float'>).
PDEP Point 3 - Interoperability What about potential PyArrow C++ binding issues? Is this straightforward to debug and fix?
TAKEAWAYS Pandas stock performance is good. :sunglasses: With foreknowledge of the nested format, data can be flattened into a DataFrame (with a column for each key). Numbers are downcasted one column at a time.
The standout issue to me is the dtype: object. Why not build a solution in Pandas or NumPy?
Comment From: hagenw
BTW, reading in a CSV file or parquet file is still faster by a factor of 5 for me when I do the reading with pyarrow and then convert to a pandas.DataFrame (but yes, using pyarrow as datatype for string is then faster then using object), compared to reading directly with pandas using pyarrow as engine.
Comment From: jkmackie
BTW, reading in a CSV file or parquet file is still faster by a factor of 5 for me when I do the reading with
pyarrowand then convert to apandas.DataFrame(but yes, usingpyarrowas datatype for string is then faster then usingobject), compared to reading directly withpandasusingpyarrowas engine.
@hagenw Would you kindly explain the below result? Looks like parquet uses a lot more peak RAM.
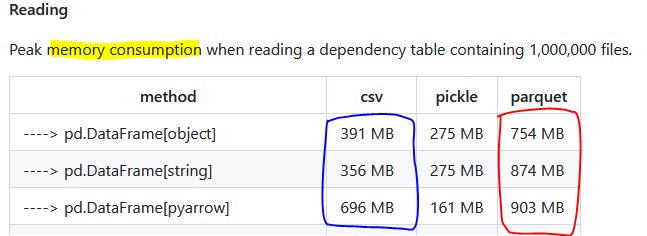
Windows users: In general, what is the large discrepancy between DataFrame memory shown by df.info(memory_usage = 'deep') versus Windows Task Manager (below is a Task Manager memory metric pic)? What is the right 'real-world' memory metric?
Comment From: hagenw
I measured peak memory consumption with memray, but I'm not completely sure if I did it correctly.
I have some updated results in the dev branch (https://github.com/audeering/audb/tree/dev/benchmarks), there we see the following
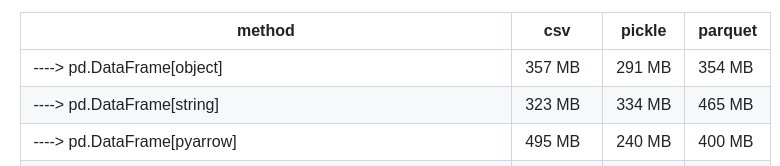
So it seems to be more equal. The code I used to measure memory consumption is available at https://github.com/audeering/audb/blob/44de33f0fea1f4d003882d674dc696a8f0cfe95d/benchmarks/benchmark-dependencies-save-and-load.py. That uses memray and writes the results to binary files that you need to inspect afterwards to extract the result.
Comment From: ebuchlin
There have been / are some efforts to reduce the size of pandas (#30741), these efforts should not be wasted by a dependency which could perhaps remain optional (although I have no idea whether this is feasible). +120MB multiplied by the number of installs/environments/images/CI runs is not so small. It takes more time to download and install, more network usage, more storage... It's neither green, nor inclusive for situations/people/institutes/countries where resources are not as easily available as where these decisions are taken.
Comment From: WillAyd
@susmitpy @dwgillies @admajaus pinging as the people that I think mentioned lambda in this thread.
AWS already has a tool called "AWS SDK for pandas" which itself requires pyarrow. There might be confusion on how AWS counts size limits (see https://github.com/aws/aws-sdk-pandas/issues/2761) but looks like it is definitely possible to run pandas + pyarrow in lambda.
Does this cover the concern for that platform?
Comment From: susmitpy
@WillAyd
More often than not we need more than one library in an aws lambda function. There is a hard set limit of 250 MB. With pandas increasing from 70 MB to 190 MB (according to one of the posts above) that leaves only 60 MB for other libraries. Pandas being so helpful, powerful and convenient is always the go to choice for dealing with data, however it being the cause due to which "along with pandas you cannot use more 1-2 libraries" will be a big issue.
cc: @dwgillies @admajaus
Comment From: WillAyd
Have you tried the layer in the link above? It is not going to be a 120 MB increase because AWS is not building a pyarrow wheel with all of the same options - looks like they remove Gandiva and Flight support
Comment From: susmitpy
@WillAyd Just tried it.
179 MB is the layer's size.
Comment From: WillAyd
Very helpful thanks. And the size of your current pandas + numpy + botocore + fastparquet images are significantly smaller than that?
Comment From: susmitpy
I don't think that's a proper comparison as AWS data Wrangler will also have support to read parquet files for which for now I resort to fastparquet for it's smaller size.
On Thu, 9 May 2024, 19:28 William Ayd, @.***> wrote:
Very helpful thanks. And the size of your current pandas + numpy + botocore images are signifcantly smaller than that?
— Reply to this email directly, view it on GitHub https://github.com/pandas-dev/pandas/issues/54466#issuecomment-2102716066, or unsubscribe https://github.com/notifications/unsubscribe-auth/AIGHCM3KKESGOBDORQENI23ZBN6HNAVCNFSM6AAAAAA3JOMQ4KVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCMBSG4YTMMBWGY . You are receiving this because you were mentioned.Message ID: @.***>
Comment From: susmitpy
Also to fetch files from S3 while avoiding downloading file and then loading, s3fs is required which I guess won't be required when using AWS sdk (not sure though).
Comment From: WillAyd
Yea ultimately what I'm trying to guage is how big of a difference it is. I don't have access to any lambda environments, but locally if I install your stack of pandas + numpy + fastparquet + botocore I get the following installation sizes in my site-packages folder:
75M pandas
39M numpy
37M numpy.libs
25M botocore
16M pip
7.9M fastparquet
Adding up to almost 200 MB just from those packages alone.
If AWS is already distributing an image with pyarrow that is smaller than this then I'm unsure about the apprehension to this proposal on account of lambda environments. Is there a significant use case why users cannot use the already distributed AWS environment that includes pandas + pyarrow and if so why should that be something that holds pandas developers back from requiring pyarrow?
Comment From: h-vetinari
As of a few hours ago, there's a pyarrow-core on conda-forge (only for the latest v16), which should substantially cut down on the foot print.
The split of the cloud provider bindings out of core hasn't happened yet, but will further reduce the footprint once it happens.
Comment From: MarcoGorelli
I honestly don't understand how mandating a 170% increase in the effective size of a pandas installation (70MB to 190MB, from the numbers in the quoted text) can be considered okay.
I think the pdep text wasn't precise here - pandas and numpy each require about 70MB (in fact, a bit more now, I just checked). So the percentage of the increase is more like 82% - not 170%. Still quite a lot, I don't mean to minimise it, but at lot less than has been stated here.
It's good to see that on the conda-forge side, things have become smaller. For the PyPI package, however, my understanding is that this is unlikely to happen any time soon
Have you tried the layer in the link above
I just tried this, and indeed, it works - pandas 2.2.2 and pyarrow 14.0.1 are included. I don't think it's as flexible as being able to install whichever versions you want, but it does seem like there is a workable way to use pandas in Lambda
Comment From: tazzben
I would ask the pandas developers to consider the impact of this decision on PyScript/Pyodide. The ability to develop statistical tools that can be deployed as a web app (where it is using their CPU and not a server) is a game changer, but it does mean the web browser is downloading all the packages the site needs. I'd also note, that many packages (e.g., Scipy) require numpy, so the likely result is that both packages will end up being downloaded.
I'd also ask the developers consider numba (outside the WASM environment). A lot of scientific code is accelerated by numba which implements parts of numpy (among other things). My point is that it is unlikely this code can just be replaced with pyarrow code. Again, both will end up being installed.
Comment From: opresml
I think more people will comment on this in the form of backlash when they realize it has been done without them being aware. While we understand the value of PyArrow, it is not an absolute necessity for pandas as demonstrated by historical performance and adoption. PyArrow is already available for those that need/want it. Pandas should have pyarrow integration but not as a requirement for Pandas to function. As a pyodide/wasm developer , I can attest that payload size is paramount. Pyarrow is just too big. Make the PyArrow integration easy, but not mandatory. Think about more than the big data use case.
Comment From: sam-s
Updating to numpy2 required reinstalling pyarrow.
Then I got
Windows fatal exception: code 0xc0000139
Thread 0x00009640 (most recent call first):
File "<frozen importlib._bootstrap>", line 488 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 1289 in create_module
File "<frozen importlib._bootstrap>", line 813 in module_from_spec
File "<frozen importlib._bootstrap>", line 921 in _load_unlocked
File "<frozen importlib._bootstrap>", line 1331 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 1360 in _find_and_load
File "${localappdata}\miniconda3\envs\c312\Lib\site-packages\pyarrow\__init__.py", line 65 in <module>
File "<frozen importlib._bootstrap>", line 488 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 995 in exec_module
File "<frozen importlib._bootstrap>", line 935 in _load_unlocked
File "<frozen importlib._bootstrap>", line 1331 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 1360 in _find_and_load
File "${localappdata}\miniconda3\envs\c312\Lib\site-packages\pandas\compat\pyarrow.py", line 8 in <module>
File "<frozen importlib._bootstrap>", line 488 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 995 in exec_module
File "<frozen importlib._bootstrap>", line 935 in _load_unlocked
File "<frozen importlib._bootstrap>", line 1331 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 1360 in _find_and_load
File "${localappdata}\miniconda3\envs\c312\Lib\site-packages\pandas\compat\__init__.py", line 27 in <module>
File "<frozen importlib._bootstrap>", line 488 in _call_with_frames_removed
File "<frozen importlib._bootstrap_external>", line 995 in exec_module
File "<frozen importlib._bootstrap>", line 935 in _load_unlocked
File "<frozen importlib._bootstrap>", line 1331 in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 1360 in _find_and_load
File "${localappdata}\miniconda3\envs\c312\Lib\site-packages\pandas\__init__.py", line 26 in <module>
uninstalling pyarrow removed 37(!) packages, and also removed the above error.
The point is that an extra dependency (especially such a huge one) increases fragility. I sympathize with the developers' desire to simplify their lives, but, as a user, I see only costs and no benefits in pyarrow.
Comment From: rohitbewoor-ebmpapst
Hi, Thank you for asking for feedback on this. All the points already raised about package size with pyarrow, wheels, default packages of ubuntu, etc are my concerns as well. Therefore, I propose if this is even possible: 1) Keep pandas 3.0 rollout without pyarrow. Old codes bases continue to import and use as they did before. 2) Create a totally new package e.g. pandasarrow. New projects use this always. Old projects switch to importing this if it makes sense. 3) Usually we always "import pandas as pd" and then continue. So this way a switch to either "import pandasarrow as pd" or "import pandas as pd" would be easy to do. My two cents.
Comment From: soulphish
Not to beat a dead horse, but....
I use Pandas in multiple projects, and each project has a Virtual Environment. Every new major version of python gets a virtual environment for testing the new version too. The size of these project is not huge, but now they have all increased massively, and the storage requirement for projects has increased almost exponentially.
Just something to keep in mind. I know there is talk of pyarrow being reduced in size too, which would be great. I admit, I have not read the full discussion, so this may have been covered already, and I apologize if it has been.
Comment From: agriyakhetarpal
Hi all – not to segue into the discussion about the increase in bandwidth usage and download sizes since many others have put out their thoughts about that already, but PyArrow in Pyodide has been merged and will be available in the next release: https://github.com/pyodide/pyodide/pull/4950/
Comment From: Runa7debug
I find this error in the lab of module 2-course 3 data science:
import pandas as pd # import library to read data into dataframe
Comment From: bersbersbers
It's a bit unfortunate that with pyarrow dependencies, using pandas on Python 3.13 is now effectively blocked by https://github.com/apache/arrow/issues/43519. Making pyarrow required will aggravate such issues in the future.
Comment From: miraculixx
Reading this thread, it appears that after more than 12 months of collecting feedback, most comments are not in favor of pyarrow being a dependency, or at least voice some concern. I haven't done a formal analysis, but it appears there are a few common themes:
Concerns
- Pyarrow's package size is considered to be very/too large for a mandatory dependency
- There is additional and often unwarranted complexity in pyarrow installation (e.g. version conflicts, platform not supported)
- Pyarrow's functionality is not needed for all of pandas use cases and hence having to install it seems unnecessary in these cases
Suggested paths forward
a. Make it easy to use pandas with pyarrow, yet keep it an optional dependency b. Make it easy to install pyarrow by reducing its size and installation complexity (with pandas, e.g. by reducing dependency to pyarrow-base instead of the full pyarrow)
(I may be biased in summarizing this, anyone feel free to correct this if you find your analysis is different)
Since this is a solicited feedback channel established for the community to share their thoughts regarding PDEP-10, (how) will the decision be reconsidered @phofl? Thank you for all your efforts.
Comment From: asishm
Since this is a solicited feedback channel established for the community to share their thoughts regarding PDEP-10, (how) will the decision be reconsidered @phofl? Thank you for all your efforts.
There is an open PDEP under consideration to reject pdep-10. https://github.com/pandas-dev/pandas/pull/58623 If (when?) it gets finalized, it'll get put to a vote.
Comment From: miraculixx
JupyterLite is another project that will be impacted by pyarrow becoming a required dependency, as per https://github.com/pyodide/pyodide/issues/4840 (although might be resolved by upstream https://github.com/pyodide/pyodide/issues/2933)
Comment From: agriyakhetarpal
JupyterLite is another project that will be impacted by pyarrow becoming a required dependency, as per pyodide/pyodide#4840 (although might be resolved by upstream pyodide/pyodide#2933)
PyArrow will be included in the next release for Pyodide and pandas should work correctly after that. We are planning it here: https://github.com/pyodide/pyodide/issues/5064
Comment From: jjGG
Hello Developers,
Unfortunately I do get an error upon running FragPipe22 in the library generation step.
SpecLibGen [Work dir: E:\projects\p36602\FragPipe\20250305_assessement\test_newPyPath]
E:\software\Python3_9_6\python.exe -u E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py E:\projects\p36602\FragPipe\20250305_assessement\2025-02-19-decoys-p24073_db6_TBnLepNSwissprotNDairy_20241120.fasta.fas E:\projects\p36602\FragPipe\20250305_assessement\test_newPyPath unused E:\projects\p36602\FragPipe\20250305_assessement\test_newPyPath True unused use_easypqp noiRT;noIM 63 "--unimod E:/software/FragPipe-22/FragPipe-jre-22.0/fragpipe/tools/unimod_old.xml --max_delta_unimod 0.02 --max_delta_ppm 15.0 --fragment_types [\'b\',\'y\',]" "--rt_lowess_fraction 0.0" delete_intermediate_files E:\projects\p36602\FragPipe\20250305_assessement\test_newPyPath\filelist_speclibgen.txt
E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py:18: DeprecationWarning:
Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0),
(to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries)
but was not found to be installed on your system.
If this would cause problems for you,
please provide us feedback at https://github.com/pandas-dev/pandas/issues/54466
import pandas as pd
File list provided
Traceback (most recent call last):
File "E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py", line 580, in <module>
main()
File "E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py", line 487, in main
params = easyPQPparams()
File "E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py", line 140, in __init__
self.easypqp = get_bin_path('easypqp', 'easypqp')
File "E:\software\FragPipe-22\FragPipe-jre-22.0\fragpipe\tools\speclib\gen_con_spec_lib.py", line 196, in get_bin_path_pip_CLI
rel_loc, = [e for e in files if pathlib.Path(e).stem == bin_stem]
ValueError: not enough values to unpack (expected 1, got 0)
Process 'SpecLibGen' finished, exit code: 1
Process returned non-zero exit code, stopping
How can I circumvent this? Is there a solution to this? We are using python3.9.6 as required by the developers.
Best regards
jj_gg
Comment From: MarcoGorelli
you can upgrade pandas or silence the warning