Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
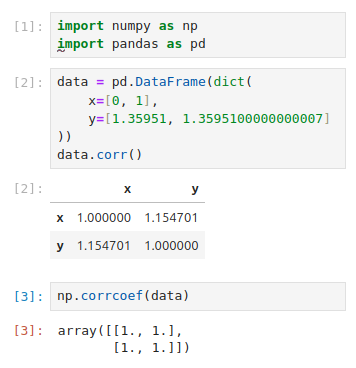
data = pd.DataFrame(dict(
x=[0, 1],
y=[1.35951, 1.3595100000000007]
))
data.corr().max().max()
Issue Description
The example above results in 1.1547005383792517.
This is similar to https://github.com/pandas-dev/pandas/issues/35135 which was closed as "not an issue with pandas, but just numerical computations" but differently to that issue which showed minuscule differences (practically negligible), I am presenting an example where the Pearson correlation is over 15% above the maximum of 1.
I was able to reproduce this on multiple machines.
I think this might warrant a mention in the documentation.
Expected Behavior
These two are perfectly correlated, so we would expect 1. 1 is the result for both:
- (data + 0.0000000000000002).corr().max().max()
- (data - 0.0000000000000002).corr().max().max()
Interestingly, using corrwith or R leads to a different result which under-estimates the correlation (but at least is not out of range, and the relative error is smaller!):
- data[['x']].corrwith(data['y']) returns 0.948683
- cor in R also returns 0.9486833
cor(c(0, 1), c(1.35951, 1.3595100000000007))
[1] 0.9486833
Installed Versions
INSTALLED VERSIONS
------------------
commit : 0691c5cf90477d3503834d983f69350f250a6ff7
python : 3.11.4
python-bits : 64
OS : Linux
OS-release : 6.8.0-55-generic
Version : #57-Ubuntu SMP PREEMPT_DYNAMIC Wed Feb 12 23:42:21 UTC 2025
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_GB.UTF-8
LOCALE : en_GB.UTF-8
pandas : 2.2.3
numpy : 1.26.3
pytz : 2023.3.post1
dateutil : 2.8.2
pip : 23.1.2
Cython : None
sphinx : None
IPython : 9.0.0.dev
adbc-driver-postgresql: None
adbc-driver-sqlite : None
bs4 : 4.12.3
blosc : None
bottleneck : None
dataframe-api-compat : None
fastparquet : None
fsspec : None
html5lib : None
hypothesis : None
gcsfs : None
jinja2 : 3.1.3
lxml.etree : None
matplotlib : 3.10.0
numba : None
numexpr : None
odfpy : None
openpyxl : None
pandas_gbq : None
psycopg2 : None
pymysql : None
pyarrow : 15.0.0
pyreadstat : None
pytest : 7.4.4
python-calamine : None
pyxlsb : None
s3fs : None
scipy : None
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlsxwriter : None
zstandard : None
tzdata : 2023.4
qtpy : None
pyqt5 : None
Comment From: krassowski
Note that numpy.corrcoef clips the values into the correct range
Due to floating point rounding the resulting array may not be Hermitian, the diagonal elements may not be 1, and the elements may not satisfy the inequality abs(a) <= 1. The real and imaginary parts are clipped to the interval [-1, 1] in an attempt to improve on that situation but is not much help in the complex case.