Hello Spring Data team! Off topic: You are awesome!
We are using spring-data-jpa with spring naming strategy and we found bug when its generating a column name for entity with property ends with single char, like for example:
- myTypeA which I'm expecting should result into my_type_a
- or myTypeB => my_type_b
spring:
jpa:
hibernate:
naming:
implicit-strategy: org.springframework.boot.orm.jpa.hibernate.SpringImplicitNamingStrategy
physical-strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
Spring Data JPA Entity
@Entity
data class MyEntity(
@Id
@GeneratedValue(strategy = IDENTITY)
val id: Long? = null,
// @Column(name = "my_type_a") // when @Column annotation is commented resulted in my_typea
val myTypeA: String = "",
// @Column(name = "my_type_b") // when @Column annotation is commented resulted in my_typeb
val myTypeB: String = "",
)
I'm expecting that myTypeA and myTypeB will be resulted into my_type_a and my_type_b,
but actual values are my_typea and my_typeb
If you look at org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy#apply method, you can see:
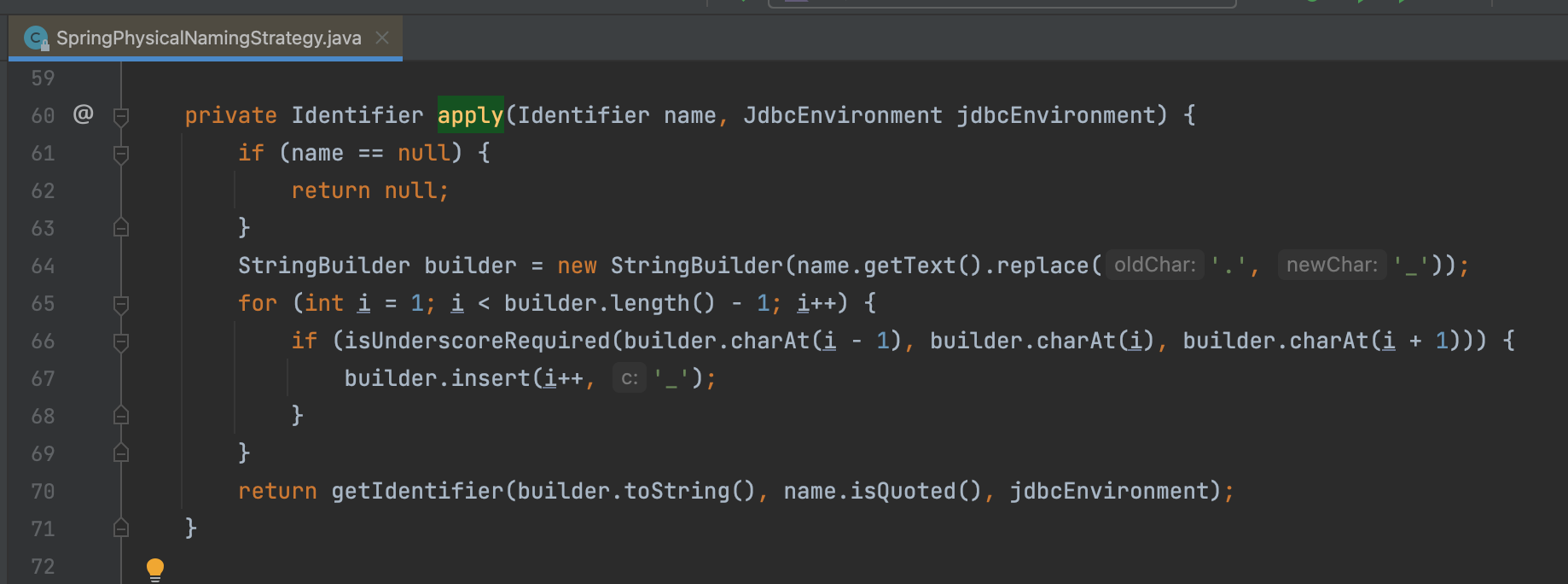
that last char is simply ignoring
isUnderscoreRequired(builder.charAt(i - 1), builder.charAt(i), builder.charAt(i + 1))
Environment: - Spring Boot 2.5.9 - JDK 11
Regards, Maksim
Comment From: snicoll
@daggerok thanks for the report. Unfortunately, the naming strategies have moved to the Hibernate project (#27352) so we don't have the freedom to make a change that would apply consistently. Could you please report that against the Hibernate project? If you do so, adding a link to the created issue here would help us track the outcome. Thanks!